WITNESS元素
WITNESS元素–离散型元素
**离散型元素:**离散型元素是为了表示所要研究的现实系统中可以看得见的、可以计量个数的物体,一般用来构建制造系统和服务系统等。主要包括:零部件(Part)、机器(Machine)、输送链(Conveyor)、缓冲区(Buffer)、车辆(Vehicle)、轨道(Track)、劳动者(Labor)、路径(Path)、模块(Module)。
零部件(Part)
零部件(Part)是一种最基本的离散型元素,它可以模拟在其他离散型元素间移动、储存和被处理的任何事物,在WITNESS中使用图标****表示。WITNESS中的零部件表述的是一个广义的概念,它既可以模拟生产系统中进行机械加工、装配、制造的零部件,微型电子元件等,也可以模拟销售过程中的产品、大公司全程处理的项目、电话交流中一个的呼叫请求、超市中川流不息的顾客、医院中的病人、机场上的行李等。WITNESS中零部件模拟的事物在系统中总是从一个地点到达另一个地点,最终被直接送出系统,或者成为最终装配品的一部分而送出系统。例如:对一个零售店进行仿真时,被销售产品(Part元素模拟)总是先存放在货架上,一旦有顾客需求,则被用于满足顾客需求而被顾客带出系统;对中国移动10086电话呼叫中心仿真时,客户咨询电话(Part元素)不断到达呼叫中心,有时需要排入队列等待客服人员服务,有时直接接受客服服务,经过一定时间的客服应答之后,客户咨询电话下线,也即退出呼叫中心系统;对手机装配线进行仿真时,手机屏幕、键盘等(Part元素模拟)不断由物料组人员送达装配线对应工位上暂存,然后逐件被装配到手机主板上,通过输送链送入下道工序,最终成为完整的手机被送出装配线。Part元素可以模拟实际系统中那些被加工、被处理的对象,这些对象在系统中仅仅存放特定长度时间(加工、存储和运输时间之和),最终要被送出系统,这些对象也称为临时实体。
用于模拟实际系统各种临时实体的零部件进入系统的方式各具特色,但是都可以通过三种方式对其临时实体进入系统的过程进行描述。WINTESS为零部件进入模型设计有三种主要方式:
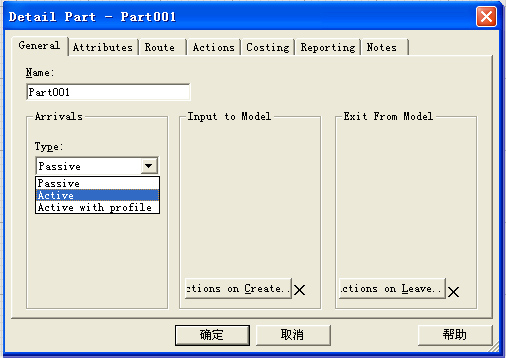
- 被动式(Passive):只要有需要,零部件可以无限量进入模型。如在生产性企业中,一些零部件堆放在仓库中,当生产需要时,可以随时把它取出来供应生产。
- 主动式(Active):零部件可以间隔固定的一段时间(例如,每隔10分钟)进入模型;可以按照一定的随机分布进入模型,如顾客到达商店的时间间隔服从均匀分布;也可以经验分布的时间间隔(例如,10分钟,20分钟,30分钟)到达模型中;
- 特殊规则的主动式(Activewithprofile):例如,一个餐馆,有50位“顾客”(零部件)在上午8点到达那里,10位顾客在上午8:01至11:59到达那里,50位在中午12点到达,50位在12点半到达等等,每星期都如此。在该方式中,建模师可以使用Activewithprofile方式对零部件到达模型的时间、时间间隔、到达最大数量等选项进行设置。
WITNESS零部件类型元素的细节设计对话框中提供了这三种方式的设计,如下图所示。
零部件以何种方式进入模型需要根据其所模拟的实际对象进入实际系统的模式来确定。例如:在使用仿真研究银行营业柜台开放时间和数量对服务效率的影响时,到银行营业厅的顾客将使用零部件类型的元素来模拟。由于在实际系统中,顾客是主动到达银行营业厅的,可以很容易想到顾客元素进入模型的方式为主动式的,但是如何确定顾客进入模型服从的规律呢?基于排队论理论,顾客到达系统的间隔时间是服从特定随机分布的,极大可能性服从指数分布,但是对于这里研究的银行营业厅系统,顾客到达是否服从指数分布?假若顾客到达间隔时间服从指数分布,那么这个指数分布的均值为多少?这些问题都需要在建模之前通过收集实际系统数据,进行统计拟合和假设检验来解决,具体实现方法参看高级教程中《仿真输入模型的构建》部分。
对于各种类型的零部件元素在建模过程中需要进行相关细节项目的设计,以实现其模拟的实际对象的数据特征和行为特性,这些细节设计在Witness仿真建模中称之为元素细节设计(DetailDesign)。零部件细节设计过程是通过该元素的细节设计对话框完成的,下面以Active方式的Part元素细节设计进行说明(其他两种类型零部件元素细节设计对话框参看后续示例教程部分),对话框如下图所示。
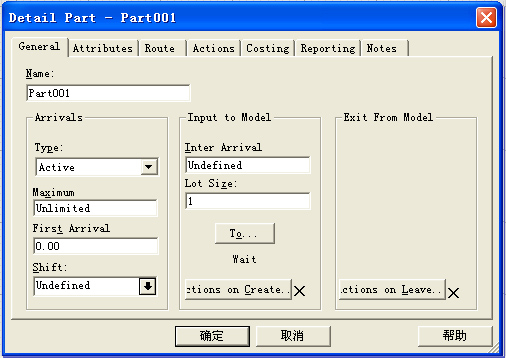
主动式零部件细节设计对话框General页面项目说明:
- Maximum:零部件进入系统的总量限制,如果没有总量限制,请保留为缺省值:Unlimited;如果有总量限制,在其下方的文本框中输入限制的数量;
- FirstArrival:第一批零件进入模型的时间点,缺省情况下第一批零件在0时刻进入模型;
- Shift:设定零部件进入系统的班次情况;
- InterArrival:前后两批零件的到达间隔时间,可以是常量、变量或者具有实数返回值的函数,或者是这些类型数据组成的实数表达式,注意不能为负数;
- LotSize:每批到达零件的批量;
- To…:用于设计该零部件进入系统后的去向,例如:进入某个队列,或直接进入某个车床上进行加工等;
- ActionsonCreate…:用于设计该零部件对象创建时所要执行的相关操作,可以是数据的计算,或者改变系统其它对象的属性等;
- ActionsonLeave…:用于设计该零部件离开系统时所要执行的相关操作;
机器(Machine)
机器(Machine)是用于模拟实际系统中获取、处理零部件对象并将其送往特定地点的对象或过程的离散型元素,在WITNESS使用图标表示。WITNESS中的机器也是一个广义的概念,它可以模拟实际生产制造系统中的特定机器设备,也可以模拟提供相关服务的柜台。例如:机器可以代表有装载、旋转、卸载、空闲和保养这五个状态的一台车床,也可以代表有空闲、工作、关闭三个状态的一个机场登记服务台(将旅客与他们的行李分开,并发放登机卡),还可以代表有焊接,空闲和保养三个状态的一个机器人焊接工等等。
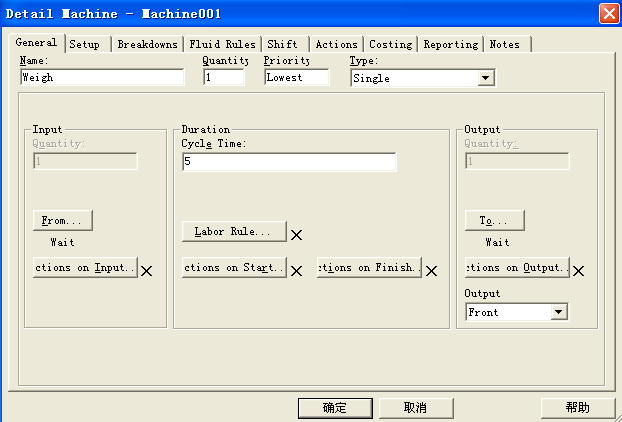
实际系统对零部件对象进行处理的过程和方式多种多样,Witness提供了七种类型的机器来建立不同类型处理过程的仿真对象:
(1)单处理机(Single)
单处理机为一次只能处理一个部件,单个部件输入单个部件输出的机器或处理过程。例如:普通车床总是装上一件零件后对该零件进行机械操作,最后的完成品还是一个零件;单个银行服务柜台总是为当前的一个顾客提供服务,服务结束后还是一个顾客离开。
(2)批处理机(Batch)
批处理机为一次同时对多个零部件进行处理,处理结束后还是输出这些数量的零部件的机器或处理过程,n个部件输入n个部件输出。例如:油漆车间对某些机械件的高温喷漆过程,总是先将特定数量的机械件送入喷漆箱,封闭后喷漆设备同时对这些机械件进行喷漆,喷漆过程结束将这些机械件送出喷漆箱,喷漆过程前后的零件数量不会改变。
(3)装配机(Assembly)
装配机为将输入的多个零部件组装成一个组件输出的机器或处理过程,m个部件输入1个部件输出。例如:汽车装配线的发动机装配工位,在输入一个车体和一个发动机部件后开始安装,安装结束后输出一个带有发动机的车体;啤酒生产线最后的打包工序输入12个零部件(12瓶啤酒)进行打包后输出一箱啤酒,即输入的零部件数量为12,输出零部件数量为1。
(4)生产机(Production)
生产机为将一个零部件输入后能输出多个零部件的机器或处理过程,1个部件输入m个部件输出。例如:钢板切割设备输入单片钢板,加工后会输出多件钢材和一些边角料;啤酒销售柜台拆开啤酒包装箱的过程,输入的为一箱啤酒,输出的为12瓶啤酒。需要注意的是,生产机不仅输出原部件,而且输出带有规定生产数目的附加零部件,例如:啤酒拆卸过程,输入的为一个啤酒箱,输出的为12瓶啤酒,拆卸后的输出零件不仅包括一个空的啤酒箱,还包括12瓶啤酒。
(5)通用机(General)
通用机为输入零件数量和输出零件数量都可以进行自定义的一类机器或者处理过程,m个部件输入n个部件输出。例如:某台钢板切割机器输入3块钢板,每块钢板可以切割为4等份的钢材,这样需要使用通用机模拟该设备,该设备的输入零部件数量为3,输出零部件数量为3*4=12件。
(6)多周期处理机(MultipleCycle)
多周期处理机为一个作业工序需要进行连续的多道处理过程的机器或者处理过程,其一个作业工序可以包括多个处理周期,在每个处理周期都可以设置输入的零部件及数量以及输出零部件的类型和数量。该类机器可以模拟这样的装配过程:该装配过程在一个工位完成,该装配过程先要对1个A和2个B进行20s的组装,再提取2个C组装到A和B的组装成品上,组装时间为30S;再提取1个D进行10S的组装。还可以模拟半自动机床的作业过程,某半自动机床在上料的10S和下料的20S需要一名工人协助,而在上料后将进行1000s的自动加工过程,自动加工过程不需要工人协助。
(7)多工作站机(MultipleStation)
多工作站机为多台联结在一起的机器设备组成的工作机组,零部件在该工作机组上按照同样的顺序和作业方式接受加工处理。
设定机器元素类型可以通过对Machine类型元素细节对话框的Type项进行选择,参看下图所示。
输送链(Conveyor)
输送链是可以模拟系统两点间零部件运输的传送装置的离散性元素,在WITNESS中使用图标表示。输送链可以模拟皮带输送链和滚轴输送链,例如:发动机曲轴生产线上的滚轴输送链,机场运送行李的传送带,汽车装配系统中的地链,手机装配线上的皮带输送链等。
Witness提供了四种类型的输送链:移位固定式(IndexedFixed)、移位队列式(IndexedQueuing)、连续固定式(ContinuousFixed)、连续队列式(ContinuousQueuing),可以在输送链的细节对话框中进行选择设定,如下图所示。
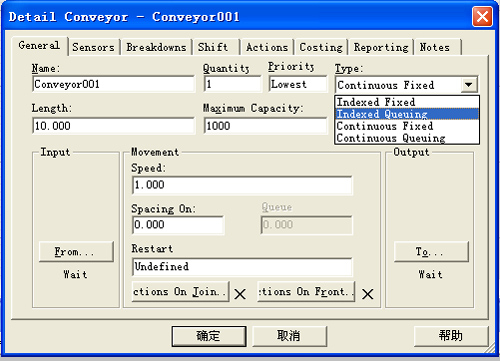
固定式Fixed:固定式输送链表示当零部件送达该类输送链后,这些零部件按照相同的速度向前移动,它们之间的距离保持固定不变,即当某个零部件移动到输送链前端,但是不能向外输出时,整个输送链就会停止移动,其他零部件也将保持在原来的位置不动。经常用于模拟皮带输送链,当输送链前端停止时,整个皮带将会停止,其他位置的零部件将不再向前移动。
队列式Queuing:队列式输送链允许零部件进行移动堆积,即当某个零部件移动到输送链前端,但是不能向外输出时,后面的零部件依然会向前端移动,直至靠近其前面额零部件不能再向前移动为止。该类输送链经常用于模拟滚轴输送链,当输送链前端停止时,后面的滚轴依然将零部件向前运输。
对于固定式和队列式输送链,可以使用下面两幅图进行比较:
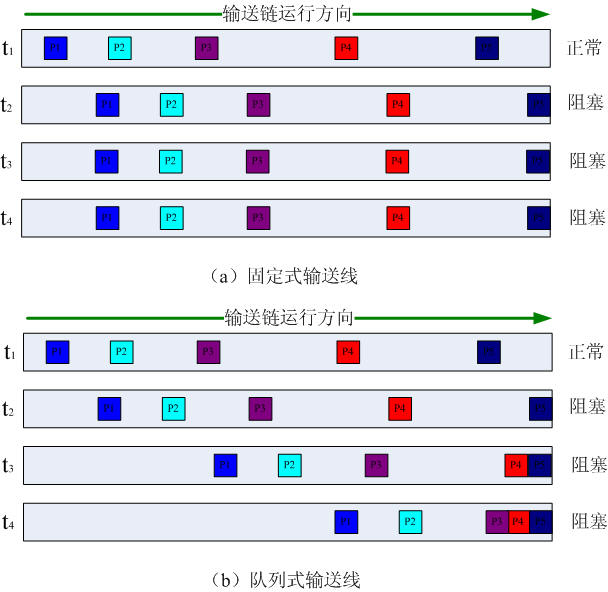
从上面两幅图上可以看出:
在时间段[t1-t2]内输送链均为正常移动,两种类型输送链上的零件均向前移动,状态表现一致。
到了时间点t2时,零件P5到达输送链的前端,但是处于阻塞状态不能离开输送链,在时间段[t2-t3-t4]输送链均处于阻塞状态,这时两类输送链上的零件有不同的状态表现:(1)固定式输送链上的零件之间需要保持距离不变,由于P5不能向前移动,所以后续的所有零件都不能向前移动;(2)队列式输送链上的零件可以不断向前移动,直至靠近其前面的零件。所以在t3时刻,P4移动到P5左侧;t4时刻P3移动到P4左侧。
移位式Indexed:移位式输送链模拟的输送链是由很多零件放置位、放置沟槽组成的,每个放置位只能放置一个零件。零件从一个放置位移动到下一个放置位需要的时间称为移位时间(IndexTime)。
连续式Continuous:连续式输送链模拟的输送链为平整的连续输送链,没有严格意义上的放置位划分,只要零件的长度在输送链上可以容纳下,就不会严格区分零件的放置点。当一条连续输送链长度为500cm时,运输的零件为A(长50cm)和B(长100cm),如果这些零件紧挨着送上该输送链,输送链上可能运输的零件组合为:AAAAAAAAB、AAAABBB、AABBBB、BBBBB,因为这些组合的总长度均为500cm;不可能在输送链上出现的零件组合为BBBBAAAA,因为该组合零件的总长度已经超过了输送链的长度了。
移位式和连续式输送链的区别可以用下图进行比较。在移位式输送链中,如图(a),不论零件的长度多么的小(当然,零件的长度必须不大于输送链的一个放置位的长度),该零件都将占据一个放置位,如图中的零件P3,这样在输送链上最多只能放置9个零件。在连续式输送链上能够放置零件的数量同输送链长度和每个零件的长度有关,因为没有严格的位置限制,零件可以一个挨着一个,如图(b)所示。
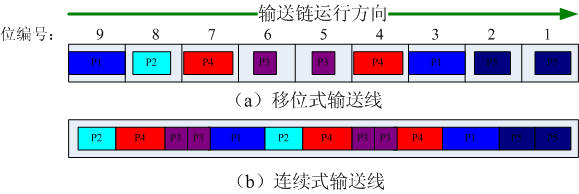
关于移位式输送线放置位的说明:
上图(a)为具有9个放置位的移位式输送线示意图,零部件总是从输送链的尾端Rear处进入输送链,即从编号9的放置位进入输送链,然后依次运行到前面的放置位,直至放置位1处离开输送线,即输送链的前端Front,即移位式输送链放置位编号是沿着输送链运行方向逐渐递减的。
缓冲区(Buffer)
缓冲区是用于模拟存放零部件元素的离散型元素,在Witness中使用图标表示,缓冲区是存放部件的离散元素。缓冲区可以表示仓库、线边库存、柜台前的队列等,例如汽车生产企业原材料仓库、成品仓库,装配线旁的零件暂存区,手机组装线边的零件储备箱,超市的货架,影剧院售票处的队列等。
缓冲区是一种被动型元素,既不能像机器元素一样主动获取部件,也不能主动将自身存放的部件运送给其他元素;它的部件存取依靠系统中其他元素主动的推或拉。我们可利用缓冲区规则,使用另一个元素把部件送进缓冲区或者从缓冲区中取出来。部件在缓冲区内还按一定的顺序整齐排列(例如,先进先出,后进先出)。
车辆(Vehicle)
车辆是用于模拟实际系统运载工具的一种离散型元素,在Witness中使用图标表示。使用车辆可以将一个或多个零部件从一个地点运载到另一个地点,车辆元素可以表示卡车、客车、铲车、AGV等。
车辆必须沿着轨道(track)运动。建立了车辆模型之后,必须建立该车辆所处的运输轨道环境,然后车辆才可以实现相关的装、卸载和运输作业。
轨道(Track)
轨道是用于模拟实际系统中的道路或者AGV运输轨道的离散型元素,在Witness中使用图标表示。车辆所走的路径是由一系列轨道组成的。每条轨道都是单向的;假如你需要一条双向的轨道,只需定义两条沿相同线路但方向相反的轨道就可以了。车辆在“尾部”(rear)进入轨道并向“前部”(front)运动。一旦到达前部,该车辆可以进行装载,卸载或其它的操作。然后它将移动到下一条路线的尾部并开始向那条路线的前面运动。
劳动者(Labor)
劳动者以模拟系统中的共享资源的离散型元素,在Witness中使用图标表示。劳动者可以模拟实际系统中的工人,也可以模拟实际系统中的维修工具等,不论是工人还是工具,他们都具有为其他元素共享的属性。例如:如果模拟的是工人,该工人可能需要同时看护多台半自动机床,为机床进行上、下料操作,当有两台以上的机床同时需要上或下料时,就会出现共享冲突,一名工人不能同时对两台机床进行操作,必然会有一台机床需要等待,进而影响整个系统的绩效。如果模拟的是工具,该工具可能在多台设备或者多项操作中都需要使用它,也存在共享冲突的可能。
路径(Path)
路径是设定部件和劳动者(或者其它资源)从一个地点到达另一个地点的移动路程的离散型元素,在Witness中使用图标表示。
Path元素同Conveyor元素既有相同点,也有不同点。
相同之处是:两类元素都可以将零部件从一个地点运送到另一个地点,而且这个运送过程需要一定的时间。
不同之处是:
Path元素可以实现控制作业人员从一个地点走到另一个地点所需要的时间;同时还可以实现由劳动者搬运零部件从一个地点移动到另一个地点;但是Path运送零部件或者劳动者的过程比较简单,就是按照均匀速率从一个地点运送到另一个地点。
Conveyor元素只能够运送零部件元素,而不能运送劳动者元素;输送链上的零部件可以实现零部件是移位式的运送,还是队列式的运输;输送链上的零部件还可以在其任意的放置位离开。
总之,只有在必要时我们才使用路径。假如模型中的元素有很长的作业周期时间而它们之间的行程距离很短,那就没有必要添加路径元素而增加模型的复杂性了。路径的选用应基于建模对象的特征或者需要实现的功能,主要考察路径、轨道和车辆、输送链实现建模功能的方便性,以进行合理选用建模元素。
模组(Module)
模组是表示其他一些元素集合的离散型元素,在Witness中使用图标表示。通过模组元素,可以很容易的在简单模型的基础上构建出较大的模型,例如一个工厂由3个车间组成,每个车间由3条生产线组成,而且这些生产线的结构和作业方式相同,整个工厂结构如下图所示。
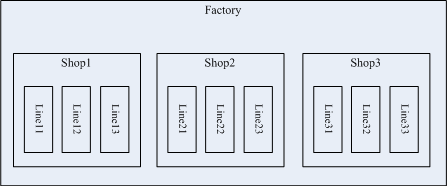
在建立该工厂仿真模型时,可以先建立一条生产线的仿真模型,可以通过如下几步使用模组元素方便快捷的构建起整个工厂的仿真模型:
(1)建立一条生产线仿真模型,例如Line11,在该模型调试结束后,将Line11构建为一个模组元素;
(2)通过复制生产线模组,建立车间仿真模型。因为该工厂的生产线在结构和作业方式基本相同,只是在作业对象和作业时间上有差异,因此可以通过复制Line11模组建立Line12和Line13的生产线仿真模组,然后对Line12和Line13进行相关的修改,并建立这三条生产线之间的物料交互逻辑,最后将这三个模组组建为Shop1模组,即完成了车间仿真模型的构建。
(3)通过复制车间模组,建立工厂仿真模型。复制Shop1模组,建立Shop2和Shop3车间仿真模组,并对Shop2和Shop3进行相关修改和调整,以及三个车间之间的物料交互逻辑,最后将这三个车间模组组建为Factory模组,完成工厂仿真模型的构建。
通过模组方式建立仿真模型,有助于提高模型结构的可读性,并易于维护和扩展,提高仿真项目的开放效率和成功率。
WITNESS系统–连续型元素
同离散型元素相对应,WITNESS连续型元素用来表示加工或服务对象是流体(连续体)的系统,比如化工生产流程、饮料生产流系统等。WITNESS连续型元素主要有四种:流体(Fluid);管道(Pipe);处理器(Processor);容器(Tank)。
流体(Fluid)
流体(Fluid)是一种可以用来模拟在系统中被加工、存储、移动的液体(啤酒、饮料、石油)、气体(天然气、蒸汽)、或者其他具有连续特征的物质(电能、热能、烟厂烟丝)等。
当流体的加工、运输和存储一般使用连续性元素Processor、Pipe和Tank来实现,在通过经过这些元素时,流体可以改变类型,例如:啤酒原料经过处理器加工后出来的就是啤酒;液化天然气通过处理器气化后出来的为气化的天然气;电能经过处理器后转变为热能等。
流体的加工、运输和存储过程有时也可以使用离散型元素来实现,例如:啤酒生产出来之后需要装入酒瓶或者易拉罐,然后进行存储或者运输;汽油在石化公司需要装入罐车成为离散型元素,然后运至加油站再转化为液体状态放入加油站的容器中;流体可以储存在零部件元素中,成为离散型元素,将流体装入零部件或者从零部件元素中取出流体需要使用机器元素来实现。
注:流体灌装或者取出只能使用单处理机、批处理机或者多工作站机,其他三种类型机器(小问题:哪三种类型的机器)不能进行流体作业。
管道(Pipe)
管道(Pipe)是用于连接处理器或者容器的运输流体的连续性元素,流体元素如果出于连续状态,在模型中的运输和移动过程均使用管道元素来实现。
流体在管道中的流动方向是同管道绘制的方向一致,即管道在屏幕上的起点为流体进入点,管道在屏幕上的终点为流体输出点。
Pipe细节设计对话框介绍:
Pipe细节设计对话框显示如下图所示,其中Capacity为管道的容量,可以通过实际系统管道的长度和直径计算获得;Rate为管道的流速;当流体进入管道或者输出管道时,流体颜色或者类型有变化时,通过对话框中FluidChange处的Input(流体进入管道时的变化设置)或Output(流体输出管道时的变化设置)两个按钮进行设置。其他项目的含义可以通过点击对话框右下角的“帮助”按钮打开WITNESS帮助文件进行查看。
当需要设置管道维修和维护规则时,点击对话框上部的Breakdown配置页进行设置;
当需要设置管道清洗规则时,点击对话框上部的Cleaning配置页进行设置;
当需要设置管道运行的班次规则时,点击对话框上部的Shift配置页进行设置;
当需要设置管道运行成本或者费率时,点击对话框上部的Costing配置页进行设置;
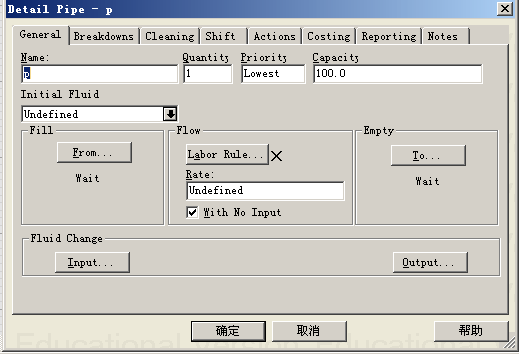
注:如果流体在两个地点元素(处理器或容器)之间的流动(运输)时间很短,可以考虑不要建立管道元素,直接使用Flow规则进行流体的流动即可,以降低模型的复杂性。
FluidChange详解:
在WITNESS中流体变化主要有两种形式:流体类型的变化和流体颜色的变化,通过点击上图对话框的FluidChange中的Input按钮,可以弹出流体变化对话框如下图
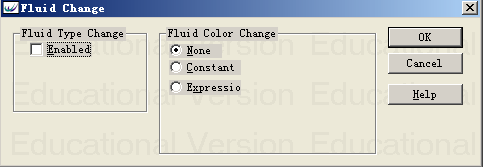
如果是流体类型发生变化,即从一种类型的流体转变为另一种类型的流体,例如:由“水”变成“啤酒”,选中上图Enabled选项框,然后进行新的流体元素选择;
如果仅仅是流体元素颜色发生变化,根据不同情况选中上图中间的“FluidColorChange”进行设置。
处理器(Processor)
处理器(Processor)是模拟对流体进行处理的设备,例如搅拌设备、净化设备等。
Processor细节设计对话框介绍:
Processor细节设计对话框显示如下图所示,其中Capacity为处理器的最大容量,MinimumProcessLevel(图片为中文操作系统中Level没有显示出来)为处理器最小处理容量,当这两个参数不相等时(肯定是Capacity>MinimumCapacity),如果输入的流体量达到最小处理容量,而输入流体中断,则处理器开始进行处理;如果输入的流体量达到最小处理容量,而输入流不中断,则一直输入到处理器的最大容量时,输入流停止,处理器开始进行处理。处理器一次处理的时间设置在Time输入框内。如果流体输入过程、输出过程或者在处理过程中需要Labor辅助作业,可以在界面对应的LaborRule进行劳动者规则设定。其他项目的含义可以通过点击对话框右下角的“帮助”按钮打开WITNESS帮助文件进行查看。
当需要设置处理器维修和维护规则时,点击对话框上部的Breakdown配置页进行设置;
当需要设置处理器清洗规则时,点击对话框上部的Cleaning配置页进行设置;
当需要设置处理器容量预警规则时,点击对话框上部的WarningLevels配置页进行设置;
当需要设置处理器运行的班次规则时,点击对话框上部的Shift配置页进行设置;
当需要设置处理器运行成本或者费率时,点击对话框上部的Costing配置页进行设置;
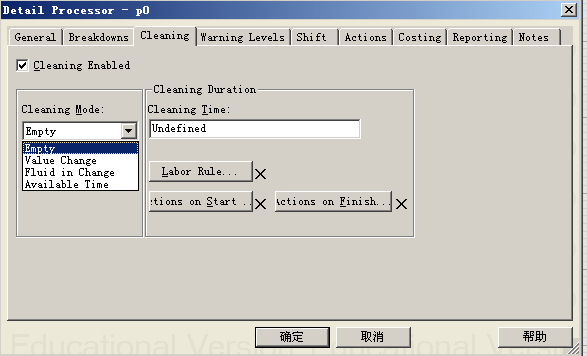
通过选择处理器细节设计对话框上的Cleaning配置页,弹出处理器清洗设置界面如下图所示,从图上可以看出,处理器的清洗激活模式有四项:
(1)Empty清空时:当处理器里面的流体输出完毕,处理器清空时发生清洗作业;
(2)ValueChange变量值变化时:当指定表达式值发生变化时,处理器发生清洗作业;
(3)FluidinChange进入的流体类型变化时:当即将进入处理器的流体同前面的流体类型不同时,处理器发生清洗作业;
(4)AvailableTime可用时间累积到特定值时:当处理器累积可用时间达到一定数值时,处理器发生清洗作业;
容器(Tank)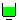
容器(Tank)是用于存放流体元素的,模拟现实系统的储罐。当流体输入容器的速率和输出容器的速率相等时,容器将一直保持为空的状态。
Tank细节设计对话框介绍:
Tank细节设计对话框显示如下图所示,其中Quantity为相同名称容器的数量,Priority为容器的优先级;Capacity为容器的最大容量;InitialFluid为容器初始化时容器存放的流体类型;InitialVolume为模型初始化时容器存放的初始化流体的量;当流体进入容器或者输出容器时,流体颜色或者类型有变化时,通过对话框中FluidChange处的Input(流体进入容器时的变化设置)或Output(流体输出容器时的变化设置)两个按钮进行设置。其他项目的含义可以通过点击对话框右下角的“帮助”按钮打开WITNESS帮助文件进行查看。
当需要设置容器清洗规则时,点击对话框上部的Cleaning配置页进行设置;
当需要设置容器容量预警规则时,点击对话框上部的WarningLevels配置页进行设置;
当需要设置容器运行的班次规则时,点击对话框上部的Shift配置页进行设置;
当需要设置容器运行成本或者费率时,点击对话框上部的Costing配置页进行设置;
容器和处理器元素的异同:
从元素细节设置对话框,可以看出容器和处理器元素存在如下方面的不同之处:
(1)处理器可以设置维修或维护规则,而容器不能;
(2)处理器容量设置有两项:最大容量和最小处理容量,而容器只有一个最大容量;
(3)流体进入处理器之后,需要经过一段处理时间之后才能够流出处理器,而流体进入容器后,只要容器的输出规则有效,流体可以直接输出容器;
两者也具有很多相同之处:
(1)两者都可以存放流体;
(2)两者都具有清洗设置、报警设置、班次设置和费用设置功能;
(3)两者都可以进行流体类型的转换;
WITNESS元素–逻辑型元素
逻辑元素是用来处理数据、定制报表、建立复杂逻辑结构的元素,通过这些元素可以提高模型的质量和实现对具有复杂结构的系统的建模。主要包括:属性(Attribute);变量(Variable);分布(Distribution);函数(Function);文件(File);零部件文件(Partfile);班次(Shift)。
属性(Attribute)
属性元素是反映单个零部件、劳动者、机器或单件运输小车特性的元素。例如,我们可以用属性来形容元素的颜色、大小、技能、成本、密度、电压或数列等。
WITNESS系统提供了许多能用于部件、劳动者、车辆、机器或者单件运输小车的系统属性,例如:零部件、单件运输小车、车辆、机器和劳动者都带有“PEN,ICON,DESCandTYPE”属性;“CONTENTSandFLUID”属性用于盛放液体的部件;“STAGE,NSTAGE,R_SETUPandR_CYCLE”属性则是用于零部件的加工工艺路径相关属性。
另外我们也可以自己定义用于部件,劳动者,车辆,机器或单件运输小车的属性。在创建零部件属性时,可以将它分配给十一个组(0组–10组)中的任何一组,然后在零部件细节设置对话框属性设置页上,将该组属性分配给该零部件。设置的作用于零部件的属性元素可以是单维元素也可以是数组形式。
当创建劳动者、单件运输小车、机器或车辆的属性时,必须把这些属性分配给0组。劳动者、单件运输小车、机器和车辆的属性只能是单维元素,而不能是数组。
可以在仿真的过程中改变属性的值,一般使用元素细节对话框中各种类型的“Actionon****”来设置、检查或改变任何属性的值。例如,一个部件的“颜色”属性的值开始是“灰”,在部件通过了一台“着色”机器之后变成了红色,则可以在“着色”机器的“ActiononFinish”中写入:颜色=”红”,来实现零部件颜色属性值的改变。
变量(Variable)
变量是用于存储特定数据的元素。在定义一个变量时,需要设置其存储数据的数据类型,主要有四种:整型、实数型、名型、字符型。
WITNESS的四种数据类型:
(1)整型(integer)
整型变量用来存储不包含小数点部分的数字。在witness中,可以是-2147483648到+2147483647之间的整数。
使用整数变量能够比较精确的存储数据,并且处理速度比比实数要快。但是由于整数的“循环”性,可能会使得它们过大或过小。例如:
2147483647+1=-2147483648
-2147483647-2=2147483647
(2)实型(real)
实型变量可以存储由数字(0~9)、小数点和正负号组成的数据。范围为(3.4E-38,3.4E38);
(3)名型(name)
名型(name)变量用来存储witness仿真系统组成元素的名称。例如:
widget
miller(3)
注:函数、数值型变量、数值型属性不能够存储为名型数据。
(4)字符型(string)
字符型变量用来存储不具有计算能力的字符型数据。字符型数据是由汉字和ASCII字符集中可打印字符(英文字符、数字字符、空格以及其他专用字符)组成,长度范围是0~4095个字符。
字符运算符
=比较前后两个字符串是否相同;
+连接两个字符串
=对字符型数据赋值
如果连接操作得出的字符型数据长度超出长度范围,witness显示出错信息。
特殊用途字符串
字符型数据可以存储任何键盘上的字符。反斜线字符()却是一个特殊的字符。
"向字符串中引入一个引号(“)。引号标识字符的结束。
\向字符串中引入一个反斜线()。
\n向字符串中引入换行符。
\r向字符串中引入回车。
\t向字符串中引入8个空格(TAB)字符。
\f向字符串中引入走纸字符。如果是打印(PRINT)操作,交互窗口被清空;如果是写(write)操作,将另起一页进行写入。
WITNESS变量元素的三种类型:
(1)系统变量。这些变量是系统已经创建好了(I,M,N,TIME,VTYPE和ELEMENT)的,并且具有特殊意义的变量,它们存储仿真中常用的数据,例如,TIME表示现在的仿真时钟。
(2)全局变量。全局变量是我们自己利用“Define,Display和Detail”过程创建的作为Witness元素的变量。
与局部变量比较起来,用全局变量的好处在于:
柔性:可以从模型的任何地方检查或更新一个全局变量的值。例如,变量“TOTAL_SHIPPED”能被模型中用于将部件送出模型的所有的元素更新。同样,任何函数,行为规则等等都可以读取“TOTAL_SHIPPED”变量中包含的值。
能生成全局变量的统计报告,但不能生成局部变量的。
能在模型中可视化动态显示全局变量和它们的值。
全局变量可以被设定为数组,我们能通过给一个全局变量1以上的下标来创建数组(行、列和数据表格),最多能创建15维的数组。
能创建一个整型或实数型的变量为动态变量,这意味着它能容纳多个值,而且该变量的长度可以动态增加或减少。在仿真运行之前,不能确定该变量需要存放的数据数量时,使用动态变量最为有效。例如,仿真过程需要使用变量shipTime来统计每个零部件离开模型的仿真时间,在仿真开始不知道在仿真运行过程中会有多少个零部件离开系统,因而就不容易确定变量shipTime数组的长度,这时设定shipTime为动态变量,在零部件离开系统时通过RecordRealValue(shipTime,Time)函数将当前仿真时间记录进动态变量shipTIme,则当第一个部件离开时shipTime中存放了1个值,其长度为1;当第二个部件离开时shipTime存放了2个值,则其长度增加为2;以此类推。
(3)局部变量。局部变量是一个我们能自己在使用它的活动或函数中创建的变量。局部变量只能是一个数,而不能是带有下标的数组。
局部变量的定义方式如下:
DIM变量名{AS数据类型}{!注释}
如果省略了数据类型的定义,系统赋予变量默认的数据类型为整型integer。
用局部变量的好处在于:
安全。局部变量只有在一个行为(action)或函数执行的时候才存在,所以不可能在另一个行为(action)或函数中使用或修改它。例如,变量“TOTAL_SHIPPED”已在一个机器的“action”中被定义了,直到结束它都只能被那一系列行为更新或读取,而不能被这台机器的其它行为或模型中的其它元素更新或读取。
快速。当行为和函数使用局部变量而不是全局变量时,它们能被更快地执行。c.方便。局部变量在使用它们的行为中被定义,不必像全局变量那样先定义它们。
分布(Distribution)
分布元素是一个可以用来描述经验分布的逻辑性元素。当模型中相关数据服从标准的随机分布时,可以直接使用WITNESS提供的标准随机分布来描述。当模型中出现的数据不服从标准的随机分布,但是又具有特定的规律时,可以使用分布元素定义经验随机分布。例如:对老菜馆饭店的服务员数量及班次进行优化仿真时,需要根据一天当中各个时段顾客到达规律和数量来配备合适数量的服务员,通过观察发现顾客到达并不服从标准的随机分布,但是也具有一定的规律,就是在每天的11:00-13:00、17:00-19:00之间到达的人数较多,而在其他时间到达的人数相对较少,这时可以根据收集到的数据定义一个描述顾客到达饭店的规律。
Witness提供了一些标准分布。其中有一些是将一系列理论分布返回到随机样本的分布。Witness包含的理论分布曾在很长一段时间内被广泛研究并且被认为在仿真中是最有用的。还有一些是一系列整数和实数的分布。当使用一个标准分布时,必须为其输入一个伪随机数流和参数。
假如没有标准分布适用的情况,或者我们收集的现实生活中的数据是在未研究领域中的,我们可能需要在Witness中建立自己的分布并从中采样。我们能创建整型,实数型和名称型的分布,并且它们可以是离散(从分布中选择实际值)的或是连续的(从一串连续值中选择一个值)。
总的来说,假如我们有详尽的现实生活的数据,那就创建自己的分布。如果没有,那么就选择Witness提供的最适当的标准分布。
函数(Function)
函数元素是能返回有关模型状态的信息或者使得模型显得更具有真实性的一组命令集合。
Witness提供了大量能直接使用的系统函数,例如Nparts(Buffer1)函数可以返回当前Buffer1中的零件数量;NShip(A)可以返回截止目前为止,使用Ship的方式离开系统的零部件A的数量。
同时我们也可以使用WITNESS的函数元素创建自己的函数,以实现独特的数学计算或者相关功能操作。例如,假设在计算一台机器的周期时间时要考虑多种因素,而我们在周期时间表达式中的输入又不能超过一行,在这种情况下,我们就可以自己创建一个函数,想写多少行就写多少行,然后只要把这个函数的名称输入这台机器的周期时间表达式区域就行了。
函数元素细节设计对话框如下图所示,右侧Type表示该函数返回值的类型,选中Integer、Real、Name或者String表示该函数将返回对应类型的数值(每个函数只能返回一种类型的数值),此时函数必须以Return语句结束;选中Void表示该函数不需要返回函数值,即该函数只是需要进行相关的数据处理即可。
函数元素还可以设置参数,通过细节设计界面右侧的Add/Remove…按钮来实现。
函数体通过点击界面下面的Action…进行设计。
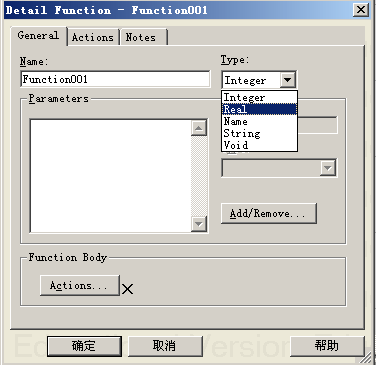
文件(File)
文件是可以使我们从仿真模型外部将数值输入模型(从一个“READ”型文件)或从模型中输出值(到一个“WRITE”型文件)的一个元素。例如,我们能从其他软件生成的文件读入如周期时间这样的值,或者生成适当的报告。
使用文件时我们应注意以下几点:
可以用文字处理工具或文本编辑工具(或其它能生成简单ASCII文本文件的程序)来创建“READ”文件。在这样的文件中以“!”符号开头的行被略去不读。
不要在仿真运行时对同一个文件进行读和写的操作。
假如有两个模型在仿真运行,应该保证它们不对同一个文件进行写入操作,但从同一个文件中读出是可行的。
假如要在运行中检查“WRITE”文件,应该在检查前先把它关掉,这样才能检查到一个完全更新了的文件。
零部件文件(Partfile)
“READ”型零部件文件是从外部数据文件读入零部件清单到模型中去的一个逻辑元素。“WRITE”型零部件文件是将零部件清单写入外部文件的逻辑元素。
零部件文件可用于从一个模型中生成输出,然后将其用于另一个模型中。零部件文件对于追溯零部件离开仿真的确切时间和零部件在那时的属性值也是很有用的。使用零部件文件应注意以下两点:
不要在一个仿真运行时对同一个文件进行读和写的操作。
假如有两个模型在仿真运行,应该保证它们不对同一个文件进行写入操作,但是从同一个文件中读出是可行的。
班次(Shift)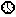
班次是一个能用来创建一个班次模式或一系列班次模式的逻辑元素,它可以用来控制系统中相关元素什么时段处于上班时间,什么时段处于下班时间。其它元素仿真班次工作时可以引用班次模式。我们可以将班次应用于下列元素:
缓冲运输网络
传送装置饼状图
流体管道
劳动者槽
机器时间序列
零部件车辆
零部件文件
班次元素细节设计对话框如下图所示,该图片演示的是一个每天工作8小时的班次元素细节设计界面。其假设仿真开始时间为凌晨0点,而该班次元素将在8点开始工作,则在班次初始时间补偿(InitialOffset)中设定了休息时间(RestTime)为480;该班次元素的主体部分为4个时间周期(Period)组成,每个时间周期由一段工作时间(WorkingTime)+一段休息时间(RestTime)+一段加班时间(Overtime)组成;该班次的主体部分为工作180分钟休息15分钟、然后工作105分钟休息60分钟(休息时间为午餐时间)、然后工作120分钟休息15分钟、最后工作75分钟之后下班休息870分钟(即下班回家)。
WITNESS元素–运输逻辑型元素
运输逻辑型元素用于建立物料运输系统。主要包括:运输网络(Network);单件运输小车(Carriers);路线集(Section);车辆站点(Station)
运输网络(Network)
运输网络把一系列的路线集,工作站和单件运输小车组合在一起。我们必须把每一个提供能量的单体元素分配到网络中去。网络的建立方式影响着其内部提供能量的单体元素的行为。
运输网络可以分为自动提供能量和路线集提供能量两种类型。如果该网络是自动提供能量型的,则单件运输小车是主动的并推动自身向被动的路线集运动。例如一个“ROBOT”单件运输小车在“LOAD_TUBE”工作站装载了一个“TESTTUBE”部件,沿着一条叫做“SECTION1”的固定路径移动,并且在“UNLOAD_TUBE”工作站把该部件卸下。如果该网络是路线集提供能量型的,路线集的行动类似于附带有铁钩的带传送装置。路线集上的铁钩钩起非活动性的单件运输小车并且把它们带往下一个元素,然后放下这些单件运输小车。最后空钩子绕回路线集的起始处,准备钩起另一个单件运输小车。例如一个“SCOOP”单件运输小车装载了一个“APPLE”部件,在一个叫做“BELT1”的路线集上把“SCOOP”单件运输小车用铁钩钩起,将它们移动到“BELT1”路线集的尾部,然后把“SCOOP”单件运输小车从铁钩上放下,空铁钩则沿着路线集返回起点。
使用运输网络应注意以下两点:
l在同一个网络中,只能使用路线集,工作站和单件运输小车;
l网络所应用的类型和班次也被应用于所有配置在该网络中的路线集,单件运输小车和工作站。
单件运输小车(Carriers)
单件运输小车沿着路线集或工作站来运输部件。它的运输方式取决于网络的类型。它可以在两个网络之间移动。
使用单件运输小车应注意以下七点:
l每个单件运输小车的最大搬运量是一个部件;
l单件运输小车可以从一个网络移动到另一个网络;
l可以在每个网络中使用多个类型的单件运输小车;
l单件运输小车只有在路线集体提供能量的网络中才能跨越式运动;
l一个单件运输小车的入口规则支持“PUSH,PERCENT和SEQUENCE”输出规则;
l可以把单件运输小车从一个模块推到另一个模块;
l当定义一个单件运输小车的时候,必须把它配置到网络中去。然而,Witness只有在运行模型的时候才会去检查该搬运工具是否配置到有效的网络中去了。
路线集(Section)
路线集是一种代表单件运输小车所走路径的提供动力的单体要素。在模型中,路线集是网络的组成部分。
使用路线集应注意以下三点:
l只有在运行模型时,Witness才会去检查这个路线集是否配置到有效的网络中去了;
l可视规则编辑器不支持路线集连接规则;
l路线集连接规则支持“PUSH,PERCENT,SEQUENCE”输出规则。
工作站(Station)
工作站是代表一个点的提供动力的单体元素,该点在路线集的起始或末尾,在这个点上,我们能对单件运输小车或者其里面的部件实施操作。共有四种类型的工作站:(1)基站(Basic)。当单件运输小车(或单件运输小车上面的部件)进入、离开或在工作站内时,可以对它们进行操作。(2)装载站(Loading)。可将部件装入单件运输小车,指派劳动者去协助装载作业,并可以在单件运输小车装载部件的时候实施操作。(3)卸载站(Unloading)。可以从一个单件运输小车里卸载部件,指派劳动者去协助卸载作业,并可以在单件运输小车卸载部件的时候实施操作。(4)停泊站(Parking)。工作与缓冲十分相象,它是一个不引起路线集堵塞的可供单件运输小车等待的空间。
使用工作站应注意以下五点:
l只有运行模型的时候,Witness才会去检查工作站是否已配置在有效的网络中。
l可视规则编辑器不支持工作站连接规则,但我们能利用可视的推、拉规则(比如“SEQUENCE”和“PERCENT”)去将部件推进或拉出合适的工作站。
l所有工作站类型都支持自由处理法(在进行处理时,单件运输小车与传送装置分离),装载站和卸载站也支持由动力推动的处理方法(单件运输小车在处理的操作中始终与传送装置机构相连)。
l不建议使用“系列”动力工作站,因为装载/卸载操作可能在进入后一个工作站之前没有完成,而且还可能因此产生意想不到的后果。
l工作站连接规则支持“PUSH,PERCENT和SEQUENCE”输出规则。
WITNESS元素–图形元素
图形元素可以将模型的运行绩效指标在仿真窗口动态的表现出来。主要包括:时间序列图(Timeseries);饼状图(Piechart);直方图(Histogram)。
时间序列图(Timeseries)
时间序列图是以图形方式来画出仿真随时间变化的值,从而表现仿真结果的图形元素。垂直的Y轴代表值,水平的X轴代表时间。
可以选择以下的一种方式来表示X轴:
仿真时间。当一个点在X轴上被标注时一个仿真的时间就被记录下来了。
表达式。不论何时,只要表达式被求值,一个标注点就被确定下来了,而且标注该点时的仿真时间被记录在X轴上。
24小时制。X轴以24小时制列出小时数。
12小时制。X轴根据12小时制列出小时数。
8小时制。X轴根据8小时制列出小时数。
小时制。X轴以1,2,3等等列出小时数。
时间序列在预测模型的趋势和周期方面是非常有用的,因为它们提供了给定值的历史数据以及静态的平均值和标准差。
时间序列图类似于一个“penplotter”:它在仿真时标注点。Witness在给定的时间间隔从模型中“读取”,并且在一个图上“标注点”,在一段时间内建立一系列的值。一旦屏幕上分配给这个时间序列图的空间用完了,这个图形会“翻页”以使新的点可以被标注。虽然Witness时间序列的标注点以一条连续的线条显示,但这条线条是将各个在仿真时间点收集的值点连接起来的标注点连线。这条连接标注点的线条仅仅说明了值的变化方向。我们可用7种不同的颜色来标注7个值。
饼状图(Piechart)
饼状图用来在仿真窗口表示仿真结果,显示如何使用一个或一组元素的图形元素。例如,我们可以用一个饼状图来分块表示一个给定时段的空闲时间,装配时间和工作时间。
直方图(Histogram)
直方图是一种在仿真窗口用竖条式的图形来表示仿真结果的图形元素。在模型中适当的地方我们可以用“record”、“drawbar”、“addbar”行为在直方图中记下值。
元素应用模型
通过一个案例模型(模型下载)描述这三种图形元素的基本应用,模型界面如下图所示.
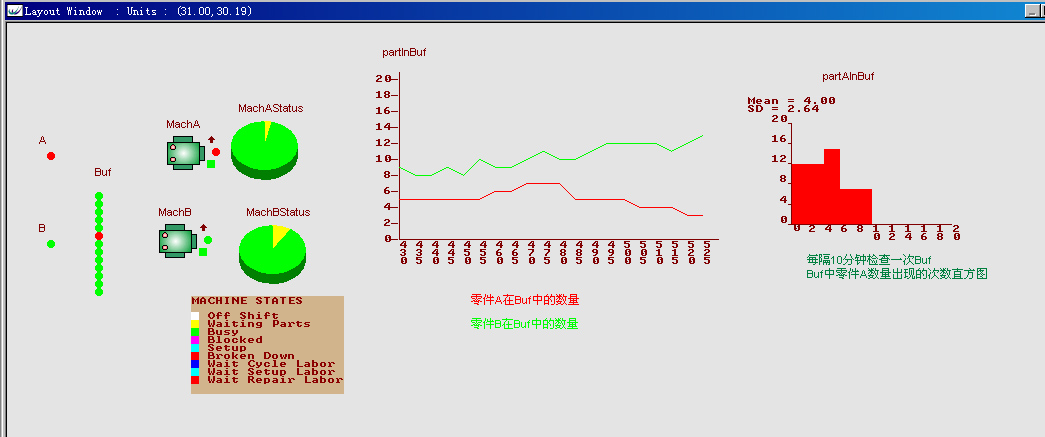
该模型模拟一个制造车间有两台机床分别加工部件A和部件B,部件A和B随机到达车间并存放在车间存放区Buf,由于部件的随机到达和机床加工时间的随机性,将导致存放区中两种部件可能会有较多的存储量。使用图形元素实时统计下列项目:
(1)使用Timeseries元素每隔5分钟实时统计Buf中部件A和部件B的存量;
(2)车间每隔10分钟检查一下车间部件的存放量,并将每次检查出的部件A存量出现的次数使用Histogram元素统计出来;
(3)使用PieChart元素动态统计两台机床的工作状态;
在建立了模型的所有元素之后,图形元素功能的具体实现如下:
(1)Timeseries元素功能实现
双击模型中名称为partInBuf的时间序列图元素,将出现时间序列图细节设计对话框,并对其相关项目设计后,界面如下:
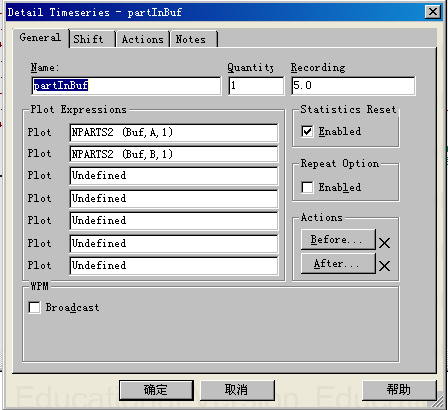
其中:
Recording项目:设置时间序列图记录数据的时间间隔,这里设置为5(分钟);
PlotExpressions项目:该项目可以设置7个数据表达式,该表达式的数据结果将以时间序列曲线的形式显示在时间序列图上,根据Recording设置间隔的大小不断记录数据,在示例中设置了两个表达式:NPARTS2(Buf,A,1),NPARTS2(Buf,B,1),这两个函数将返回在记录时刻存放区Buf中元素A和B的数量。
模型运行后,时间序列图partInBuf会呈现如下的状态:
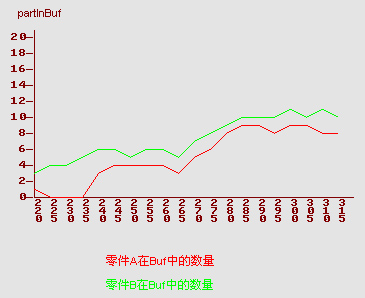
图上纵轴表示表达式的值;横轴表示记录时刻;
(2)Histogram元素功能实现
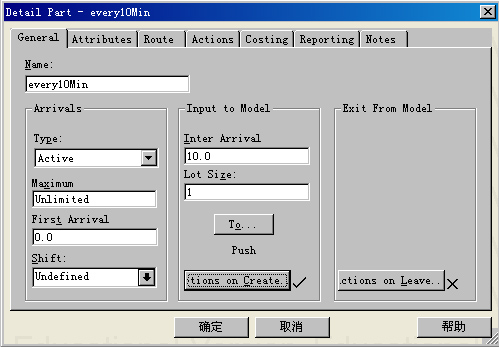
在直方图中存储数据和在时间序列图记录数据的方式是不同的,向直方图中记录数据一般使用Record函数实现,例如本例中,为了实现每隔10分钟将Buf中部件A的存储量记录到直方图partAInBuf中,设计了一个等间隔进入模型的零件元素every10Min(双击该元素,其细节设计对话框如下图),该元素每隔10分钟到达一个,到达时在其ActionsonCreate设定语句:RECORDNPARTS2(Buf,A,1)inpartAInBuf,实现将当前Buf中部件A的存量记录进partAInBuf直方图中。
运行过程中,直方图可能会呈现出如下状态:
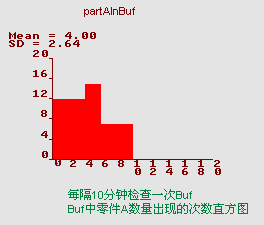
在上图中,记录立柱的划分跨度为2,即[0,1]为一组记录;[2,3]为一组记录;[4,5]为一组记录;一次类推;
在上图截止的状态下,每隔十分钟检查一次Buf中A的库存件数,其中:
有12次检查时,部件A的存量为0或1件;
有12次检查时,部件A的存量为2或3件;
有16次检查时,部件A的存量为4或5件;
有7次检查时,部件A的存量为6或7件;
有7次检查时,部件A的存量为6或7件;
在总计54次库存检查中,A的平均存量为4件,标准差为2.64(Mean=4.00,SD=2.64)。
(3)PieChart元素功能实现
使用PieChart元素动态统计两台机床的工作状态的操作方法为双击对应的饼状图元素(这里以记录机床MachA状态的饼状图MachAStatus为例说明),显示细节设计对话框并进行设计,如下图所示。
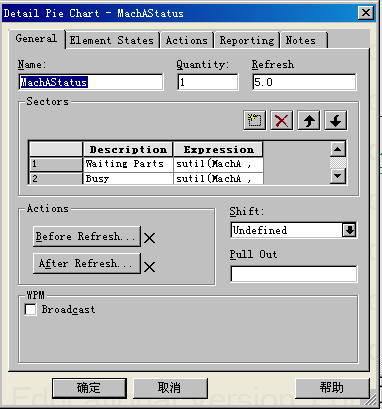
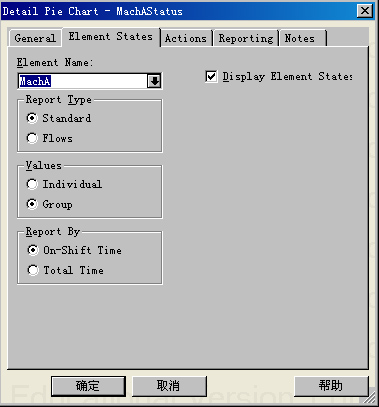
上图中,左图中只需要设定饼状图数据更新间隔周期Refresh项目即可,这里设定为每隔5分钟更新一次数据;模型中要求饼状图能够动态显示机床处于特定状态的比率,通过选择PieChart元素细节对话框中的ElementStates页,如右图所示,将DisplayElementStates前面的选项选中,然后在ElementName中选定对应的元素MachA即可。
模型运行中,饼状图动态显示的效果如下图所示:
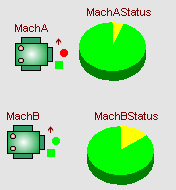
图中饼状图黄色区域显示的是对应机床空闲比率,绿色区域显示的是对应机床工作状态的比率。